
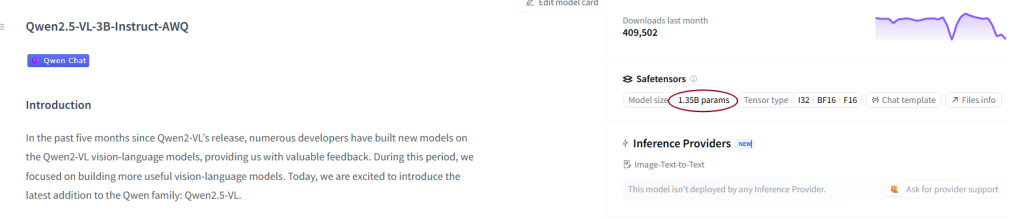
If you’ve loaded an AWQ-quantized model from Hugging Face (like Qwen2.5-VL-3B-Instruct-AWQ), you might have noticed something confusing:
👉 Hugging Face says the model has ~0.9B parameters, but the architecture is supposed to be 3B parameters. What’s going on?
What AWQ Does
AWQ (Activation-aware Weight Quantization) is a method to shrink large models:
- A normal model stores weights in 16-bit floating point (FP16/BF16).
- AWQ compresses those same weights into 4-bit integers, plus a few small helper tensors for scaling.
- On disk, this cuts memory by ~4× while keeping accuracy high.
⚡ Important: AWQ does not change the model architecture — the number of neurons and connections stay the same.
Why Hugging Face Reports Fewer Parameters
Here’s the trick: Hugging Face counts the raw tensors inside the .safetensors files, not the logical architecture.
- In FP16, every weight is stored directly, so counting tensor elements = true parameters.
- In AWQ, weights are packed:
- A big matrix like
[4096 × 4096]isn’t stored as 16M floats. - Instead, it’s compressed into fewer
int32blocks (qweight), plus tinyscaleandzerotensors.
- A big matrix like
- If you just add up the stored tensor elements, you get a much smaller number — in our example, ~0.9B instead of 3B.
So Hugging Face isn’t “wrong” — it’s just reporting compressed storage elements, not logical model parameters.
Counting Both: Compressed vs Logical
Here’s a simple script that shows both numbers side by side.
def count_compressed_params(model):
"""
Count the raw elements of tensors stored in the checkpoint.
This matches what Hugging Face Hub shows for AWQ models.
"""
return sum(p.numel() for p in model.parameters())
def count_logical_params_awq(model):
"""
Reconstruct the true architectural parameter count.
For each Linear layer: in_features * out_features (+ bias).
This is the real size of the model.
"""
total = 0
for m in model.modules():
if hasattr(m, "in_features") and hasattr(m, "out_features"):
total += m.in_features * m.out_features
if getattr(m, "bias", None) is not None:
total += m.out_features
return total
# Example
from transformers import AutoModelForImageTextToText
model_id = "Qwen/Qwen2.5-VL-3B-Instruct-AWQ"
model = AutoModelForImageTextToText.from_pretrained(
model_id,
device_map="auto",
trust_remote_code=True
)
compressed = count_compressed_params(model)
logical = count_logical_params_awq(model)
print(f"Compressed storage parameters: {compressed/1e9:.2f}B")
print(f"Logical architecture parameters: {logical/1e9:.2f}B")
Run the above code on Colab, you’ll see something like:
Compressed storage parameters: 0.98B Logical architecture parameters: 3.75B
🔎 Why the First Number Isn’t the Real Parameter Count
- Compressed storage count
- AWQ packs weights into
qweight(int32 blocks) +scales+zeros. - Each int32 holds 8 × 4-bit weights, so the tensor has fewer elements.
- Hugging Face just sums those stored elements → smaller number.
- AWQ packs weights into
- Logical parameter count
- The architecture hasn’t changed: every linear layer still has
in_features × out_featuresweights. - When you reconstruct this, you see the true size (~3B).
- This is the number that actually describes the model’s capacity.
- The architecture hasn’t changed: every linear layer still has
✅ Takeaway
- Hugging Face’s “Params” field for AWQ models = compressed storage size.
- The real model size = logical parameter count (unchanged by AWQ).
- Don’t be surprised if a “3B” model looks like 0.9B on the Hub — it’s still a 3B model under the hood.
🔑 In short:
AWQ saves memory by packing weights, and Hugging Face reports what’s stored on disk. But the model you’re running still has the same number of neurons and connections as the full-precision version.
Would you like me to add a diagram (like a weight matrix before and after AWQ packing) to make this even more intuitive for non-engineers?