
If you peel away all the complexity of modern large language models (LLMs)—billions of parameters, reinforcement learning from human feedback, retrieval-augmented generation—the essence of how they work comes down to a simple principle:
Every autoregressive LLM (decoder-only or the decoder part of encoder–decoder models) predicts a probability distribution over the next token given the context, and then generates text by either sampling from that distribution or selecting the most likely sequence.
This single sentence captures the mechanism that drives models like GPT-4, Claude, Gemini, LLaMA, T5, and beyond. Let’s unpack it carefully.
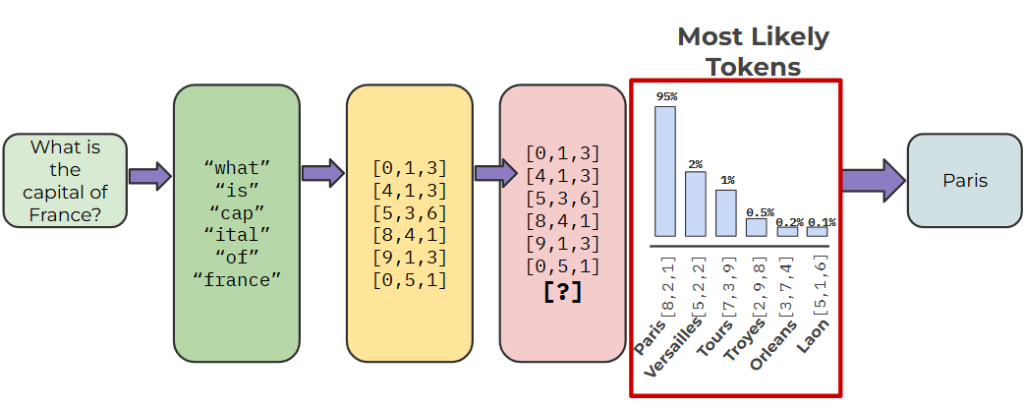
Diagram adapted from Learn Hugging Face Bootcamp on Udemy.
Tokens, Not Words
- LLMs don’t predict whole words at once. They predict tokens, which are subword units produced by a tokenizer.
- For example, “playing” may be a single token in one tokenizer, but split into “play” + “ing” in another.
- Tokenization makes the vocabulary manageable (usually 30k–100k tokens) while still flexible enough to cover diverse languages.
Probability Distributions
Mathematically, generation is modeled as a chain of conditional probabilities:
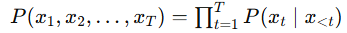
- At each step (t), the model computes (P(xt | x<t), the probability distribution over the vocabulary given all previous tokens.
- Internally, the decoder stack processes this with masked self-attention and feed-forward layers, ensuring the model can only attend to past tokens, never future ones.
- The final linear + softmax layer produces a normalized distribution across the vocabulary.
Example: given the prompt “Once upon a”, the model might assign:
- 0.40 probability to “time”
- 0.20 to “midnight”
- 0.10 to “child”
- and much smaller values to thousands of other tokens.
Sampling vs. Selecting
Once we have the distribution, we need to decode:
- Greedy decoding: always pick the highest-probability token.
- Beam search: explore multiple promising sequences in parallel, selecting the one with highest global probability.
- Sampling: select tokens stochastically according to their probabilities, often adjusted with:
- Temperature: controls randomness (low = deterministic, high = more random).
- Top-k: restrict choices to the k most likely tokens.
- Top-p (nucleus): restrict choices to the smallest set of tokens covering probability mass ≥ p.
These methods strike a balance between coherence and creativity.
Iterative Generation
- After choosing a token, it is appended to the sequence.
- The model recomputes probabilities for the next position using the updated context.
- This repeats until a stopping condition: a special (end-of-sequence) token, maximum length, or task-specific stop criteria.
This autoregressive loop is the heartbeat of every LLM.
Decoder-Only vs. Encoder–Decoder
- Decoder-only models (e.g., GPT, Claude, Gemini, LLaMA): use only the autoregressive decoder stack with causal masking.
- Encoder–decoder models (e.g., T5, BART): first use a bidirectional encoder to process the input, then an autoregressive decoder to generate outputs. Importantly, generation still happens only in the decoder, using the same next-token prediction principle.
- Encoder-only models (e.g., BERT): do not generate text autoregressively; instead they use masked language modeling for representation learning.
For a deeper dive into how encoder–decoder Transformers work, see this explainer.
Why This Matters
- LLMs are not “thinking” machines. They are statistical models that learn patterns of language by approximating token distributions.
- The richness emerges from scale: billions of parameters trained on trillions of tokens allow these probability models to capture factual knowledge, reasoning shortcuts, discourse structure, and style.
- Understanding the probability-based foundation helps explain both their strengths (fluent generation, broad knowledge) and weaknesses (hallucinations, lack of true reasoning).
Popular LLMs Built on This Principle
- GPT-4 / ChatGPT (OpenAI) – decoder-only
- Claude (Anthropic) – decoder-only
- Gemini (Google DeepMind) – decoder-only
- LLaMA / Mistral / Qwen – decoder-only
- T5 / FLAN-T5 / BART – encoder–decoder
All of them share the same autoregressive decoder mechanism: predict next-token distributions and decode into sequences.
Takeaway
When you interact with ChatGPT or any other LLM, what you’re really seeing is a machine performing this loop:
- Compute a probability distribution for the next token given the context.
- Choose a token—deterministically or by sampling.
- Append it and repeat.
Everything else—fine-tuning, alignment, safety layers, tool use—is built on top of this deceptively simple, yet powerful process. This is the core essence of every large language model.