

When it comes to similarity metrics, some popular vector database shares the same metrics. In this blog post, we will discuss the three most common similarity metrics used in vector store databases: Euclidean Distance, Cosine Similarity, and Inner Product. We’ll also spend some effort to explain why Inner Product can be used as a similarity metric.
1. Euclidean Distance
Euclidean distance is one of the most common methods for computing the similarity between vectors. Named after the ancient Greek mathematician Euclid, it calculates the straight-line distance between two points in a multi-dimensional space. It is also called “L2 distance“. This term is derived from a more general concept called “Lp spaces” in mathematics. In an Lp space, the “p” refers to the power to which each distance measurement is raised. The distances are then summed, and the p-th root of the sum gives the overall distance.
Let’s say we have two vectors A (a1, a2, …, an) and B (b1, b2, …, bn) in a n-dimensional space. The formula for Euclidean distance is as follows:
euclidean_distance = sqrt(sum for (ai-bi)2) i is from 1 to n
The concept of Euclidean distance is easy to comprehend as our brain recognizes the 2D distance or 3D distance easily. Most of us can also extend this distance definition to n-dimension comfortably. In the meantime, we need to know that Euclidean distance is decided by both the length (magnitude) of A and B and the position (or angle) between A and B. If you draw a few dots on a piece of paper, you’ll quickly realize what affects Euclidean distance. Then, you’ll need to carefully think about whether that property fits your particular use case.
2. Cosine Similarity
Cosine similarity measures the cosine of the angle between two vectors. This metric determines the orientation, not the magnitude, which often makes it a better choice for text data represented as word count vectors or TF-IDF vectors.
2.1 Definition of Cosine
For those who need some refreshing of the high-school math, here is the definition of Cosine.
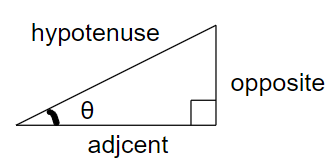
In a right-angled triangle,
the cosine of an angle = length (adjacent side) / length (hypotenuse)
The adjacent side for θ is the side that connects θ and the right angle. Opposite is also a relative term for θ as it is on the opposite side of θ. Hypotenuse connects θ and another acute angle, which is 90°-θ; it is always the longest side of a right triangle.
2.2 The Law of Cosines
In 2D space for any triangle, A, B, and C are three sides. We also use A, B, and C to represent the sides’ length.
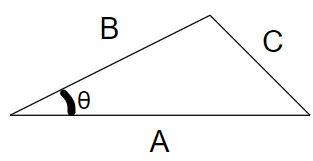
cos(θ) = (A2 + B2 – C2) / 2AB
We do not want to turn this article into a math lesson. In a nutshell, the above equation can be proved by splitting this triangle into two right triangles. Please refer to this wonderful YouTube video ‘Deriving the Law of Cosines‘ for its mathematical proof.
The law of Cosines is still valid in an n-dimensional space.
2.3 Cosine Similarity
Let’s still take 2D space and the above triangle for simplicity. We’ll take vector conventions to redraw the diagram. Since typing those math symbols in HTML is not easy, I have to switch to handwriting. Please also note that we can always derive the third side in a triangle once we know the first two sides.
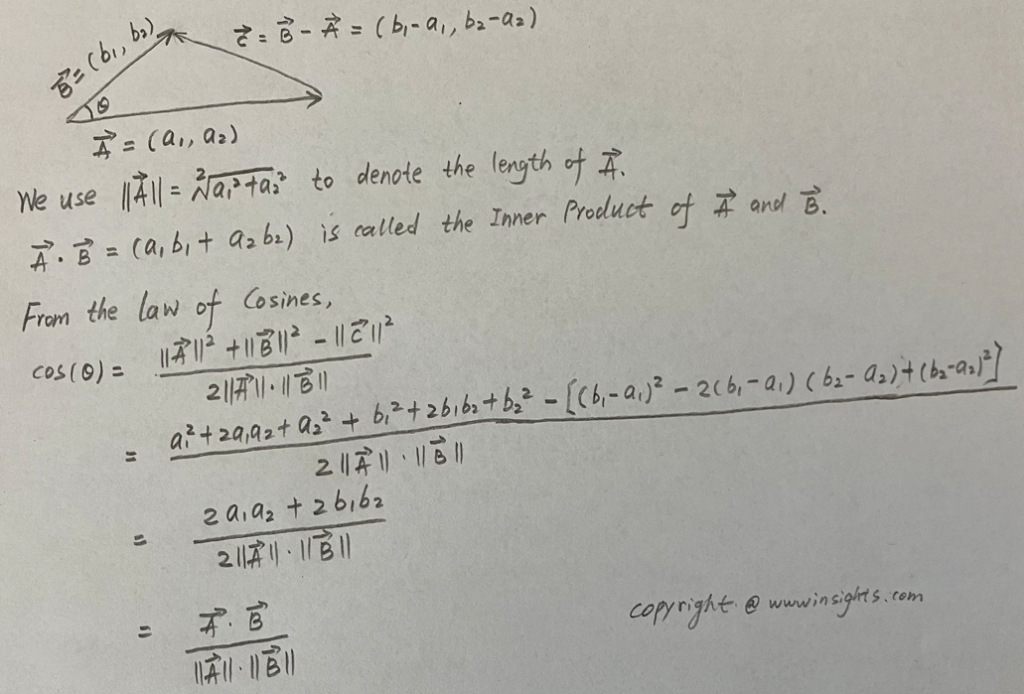
From the above proof, the Cosine similarity is:
cosine_similarity = cos(θ) = inner_product(A, B) / (||A||*||B||)
The inner product of two vectors is also called the dot product. Now we know, that Cosine Similarity is not just defined, but can be mathematically proved.
Cosine similarity ranges from -1 to 1, indicating complete dissimilarity and perfect similarity, respectively. A value of 0 indicates orthogonality or decorrelation, while negative values indicate dissimilarity.
The main takeaway is that the Cosine similarity is purely decided by the angle between two vectors. The lengths of vectors do not play any role in similarities. In some use cases, this is actually desired especially when the lengths of vectors are normalized to the same length, which is usually 1.
3. Inner Product Similarity / Dot Product Similarity
3.1 What is Inner Product Similarity / Dot Product Similarity?
We have done all the math work above, and can easily drive the inner product of two vectors A and B.
inner_product(A, B) = cos(θ) * ||A||*||B||
The inner product similarity is also called dot product similarity.
3.2 Why Inner Product can be Used as Similarity?
When the lengths of A and B are the same or normalized to the unit size (or 1), the inner product similarity becomes the Cosine Similarity. It is obvious and easy to comprehend.
3.2.1 What Affects Inner Product?
Let’s say A is the vector we already have; B and B’ are two other vectors in the space. B and B’ have the same angle as A but different lengths. The object is to find the most similar vector in the space. Since A is known, the length of A (||A||) is fixed. Now, the inner product similarity depends on two factors, the angle between A and B(B’), which is the cosine similarity, and the length of B (||B||) and B'(||B||). In other words, when two vectors have the same angles with A, the longer vector wins.
3.2.2 Where is the weirdness?
Let’s say that we have another vector called A’ in the space, which is exactly the same as A. There is the third vector A” in the space, which has the same angle but a longer length. If we adopt Inner Product Similarity, we’ll find A” is more similar to A even though A’ is identical to A. How is this possible? Does this mean that Inner Product Similarity doesn’t make sense?
3.2.3 The weirdness might be desired
Here is an example that explains A” is better than A’, which is A itself. When we do a search for a video with the title ‘How to explain ambulance?’ The search might return the video of ‘The meanings of an ambulance’ with higher viewed numbers than the video with the exact same title. Yes, you want to present a high-quality result even though the angle between titles can be slightly off. Let’s think about the above doubt we have. The key is that can ||A||, ||A’|| or ||A”|| reflect some properties that we desire? This can be very true that some models will always generate longer vectors for higher-quality content. One of Google’s models clearly says more popular videos tend to generate longer vectors. This is the perfect time to use Inner Product Similarity as the metric.
4. How to Choose Similarity Metrics?
Choosing a proper similarity metric is critical for the accuracy and performance of your application. As a rule of thumb, you need to take a close look at the process of how you generate vectors to decide which similarity metric to use.
If you use a Large Language Model (LLM) to generate vectors (also called embeddings), refer to the LLM document. Usually, the document will explain how the model was trained, whether the generated vectors are normalized, and which similarity metric is recommended.
For example, OpenAI embeddings are always normalized to 1, and its official blog recommends using Cosine Similarity although it acknowledges Inner Product (Dot Product) Similarity or Euclidean Similarity will yield the same ranking. The blog also says that ‘Cosine similarity can be computed slightly faster using just a dot product’. I think it is merely a typo since the Dot Product is part of the computing process of the Cosine Similarity. Please leave me a comment below, if you think I am wrong.
All-MiniLM-L6-v2 is trained using Cosine Similarity, so it’s better to use the same similarity to achieve better accuracy. Msmarco-bert-base-dot-v5 clearly states that it does not generate normalized vectors (embeddings) and the dot product is suitable.
5. What Similarity Metrics Popular Vector Databases Offer?
With all knowledge we accumulated from the discussion so far, we’ll take a look at some popular vector databases and the similarity metrics they offer to users.
5.1 Pinecone
When creating an index (a fancy name for a vector database) with Pinecone, you can set its metric to one of the following – euclidean, cosine (default), and dotproduct. I don’t find any constraints for those listed metrics, and I assume they hold the well-accepted definition we have discussed.
5.2 Milvus
For vectors with floating numbers, Milvus only support Euclidean Distance and Inner Product. But its inner product is effectively Cosine as it requires vectors must be normalized.
For vectors with binaries, Milvus support quite a few metrics. If the index type is BIN_FLAT, it supports Jaccard, Tanimoto, Hamming, Superstructure, and Substrcutre; if the index type is BIN_LVF_FLAT, it supports Superstructure and Substrcutre.
I am not sure whether the inner product metric still works as expected if we do not want to normalize the vectors. I guess it might. But if this really concerns you, you might choose another vector database clearly support dotproduct, such as Pinecone. When the vectors are binaries, Milvus clearly has certain advantages.
5.2 Elasticsearch Dense Vector
Elasticsearch 8.7 dense vector data type offers three similarity metrics – l2_norm (which is Euclidean Distance), dot_product, and cosine. But if you read the description closely, you’ll find out a constraint that vectors must be normalized for dot_product. So here, dot_product is merely an efficient way to calculate cosine. If you need real dot_product, you won’t be able to use Elasticsearch.
5.3 Redis Vector
Redis vector also supports the above three common metrics with a slight variation of inner dot and cosine.

If Inner Product could be subtracted by 1, that means Redis also requires vectors to be properly normalized for Inner Product.
6. Recap of Similarity Metrics
We have used quite long texts to discuss the similarity metrics, especially the differences between Cosine and Inner Product. The following table gives a brief recap.
| Similarity Metric | Which Properties Affect the Metric |
| Euclidean Distance | Length/Magnitudes and direction/angle |
| Cosine | direction/angle |
| Inner Product | Length/Magnitudes and direction/angle |
Choosing a similarity metric is an important step in your application. It affects the accuracy of the output, and also potentially limits the vector databases you can choose from.
If you have found any inaccuracies or anything would like to discuss, please feel free to leave a comment below.
I think the idea here is that since embedding is normalized, all you need to do to solve for cosine similarity is to ask for the vector inner product.