

1. Introduction
With the development of Large Language Mode (LLM), text embeddings are possible and start to be widely used. So we’ll take a look at how OpenAI enables text embeddings and use Python to do an exercise to cluster some texts in this post.
2. Text Embeddings vs. Word Embeddings
You might already hear about word embeddings before. The following table compares the two similar concepts.
| Word Embeddings | Text Embeddings | |
| Scope | focus on individual words | focus on larger chunks of text, such as phrases, sentences, or entire documents |
| Models & Techniques | typically generated using models like Word2Vec, GloVe, or FastText. These models are trained on large text corpora to learn the relationships between words based on their co-occurrences. | often generated using advanced NLP models like transformers (e.g., BERT, GPT) or other sentence encoders (e.g., Universal Sentence Encoder) |
| Applications | sentiment analysis, named entity recognition, text classification, and machine translation | document clustering, text similarity, paraphrase detection, and summarization |
3. Why it is Called Embedding?
The term “embedding” is used to describe the mapping of pieces of text into a continuous, high-dimensional space, in which the relative positions reflect their semantic and contextual relationships.
3.1 How high is the high-dimensional space?
The latest OpenAI embedding model, text-embedding-ada-002, provides a 1536-dimensional space. For comparison, the popular Word2Vec default dimension is 300. Higher dimension embeddings can capture more information about the relationships between data points, but it requires more memory and computational resources. selecting the appropriate dimensionality for embeddings involves balancing these trade-offs.
3.2 How Long the Text can be?
OpenAI text-embedding-ada-002 embedding model max input token is 8,191. You might need to understand the ‘token’ to comprehend how long it is. A token is a basic unit in Natural Language Process, and usually, you can think of 100 tokens ~ 75 English words. So the max input length of text-embedding-ada-002 is about 6,100 words. If we take an estimation of 540 words per page, this comes to roughly 11 pages of English words.
3.3 What exactly is a Dimension in OpenAI Text Embeddings?
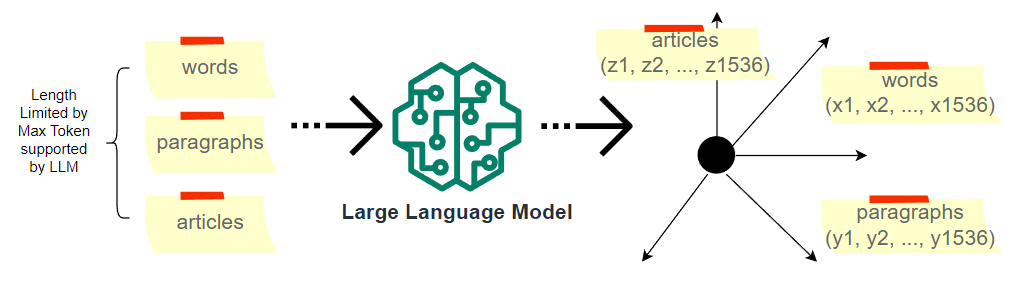
As long as the input’s token length is within the limit of 8,191, text-embedding-ada-002 will map the text into a dot in a 1,536-dimensional space. No matter if it is a single word or a long article, it will be presented by a dot. This dot has over a thousand dimensions of numeric numbers.
Can we, as humans, comprehend the physical meaning of those dimensions? Does x1 mean the color, and x2 means the location? No. Each dimension in a text embedding indeed represents a specific feature of the word or text. But these features are learned by the model during the training process and are not explicitly defined by humans. So it’s not possible for us to comprehend them anymore.
4. OpenAI Text Embeddings by Python
4.1 Python – Get OpenAI Text Embeddings
OpenAI provides a very good Python package to call its APIs. Follow our blog post to set up a python virtual environment, then install openai first.
pip install openaiThen, call the API to generate an embedding for any text.
import openai
openai.organization = 'copy-your-org-id-from-openai-account-setting'
openai.api_key = 'copy-your-api-key-here'
def get_embedding(your_text):
response = openai.Embedding.create(
input = your_text,
model = "text-embedding-ada-002"
)
return response.data[0].embedding
The returned value is a Python 1536-long list.
4.2 Python – Make clusters
We’ll run an example to see whether we can use embeddings to cluster/group texts into something meaningful. In the following function, we get text embeddings for a few dog breeds and cat breeds.
def fill_text_vectors():
text_vectors = {}
lst_breeds = ['Bernedoodle', 'Cavapoo', 'Poodle',
'German Shepherd',
'Ragdoll', 'American Shorthair', 'Scottish Fold']
for breed in lst_breeds:
text_vectors[breed] = get_embedding(breed)
return text_vectorsThen we use KMeans to cluster those embeddings into a few groups. Before using KMeans, we’ll need to install scikit-learn by pip.
pip install scikit-learnimport numpy as np
from sklearn.cluster import KMeans
def cluster(tv, num_clusters):
# Extract the list of vectors from the dictionary
vectors = list(tv.values())
# Convert the list of vectors to a NumPy array
vectors_array = np.array(vectors)
# Perform K-means clustering
kmeans = KMeans(n_clusters=num_clusters,
random_state=0,
n_init='auto').fit(vectors_array)
# Print cluster assignments for each breed and vector
for text, label in zip(tv.keys(), kmeans.labels_):
print(f"Cluster assignment for {text}: {label}")
return
For clusters of 2, you’ll get the following result. It correctly put all dog breeds into one group and all cat breeds into another breed.
Cluster assignment for Bernedoodle: 1
Cluster assignment for Cavapoo: 1
Cluster assignment for Poodle: 1
Cluster assignment for German Shepherd: 1
Cluster assignment for Ragdoll: 0
Cluster assignment for American Shorthair: 0
Cluster assignment for Scottish Fold: 0For clusters of 3, you’ll get the following result. If further put poodle and its mixes to another group.
Cluster assignment for Bernedoodle: 2
Cluster assignment for Cavapoo: 2
Cluster assignment for Poodle: 2
Cluster assignment for German Shepherd: 1
Cluster assignment for Ragdoll: 0
Cluster assignment for American Shorthair: 0
Cluster assignment for Scottish Fold: 04.3 Where to Store Embeddings
When you write an application, we do not want to call OpenAI for embeddings every time for the same text. After all, OpenAI APIs are not free and you need to pay for every call.
Putting vector data into a JASON file, and storing it in a traditional relational database like MySQL is an option. But there is a specially designed vector database, such as Pinecone you can make use of.
5 Conclusion
As you may realize now, OpenAI’s text embeddings provides developers with an easy-to-use and powerful solution. If you would like to know more details, you can refer to its official document. If you have any suggestions, please leave a comment below.