

Welcome to our technical blog, where we delve into the comprehensive guide on installing Tesseract OCR version 5 on Ubuntu. Tesseract OCR is a widely acclaimed open-source optical character recognition engine, and version 5 brings significant improvements and features. However, if you follow the official installation guide, the current Ubuntu repositories typically offer version 4.1.1, which might not meet the needs of those requiring the latest enhancements. This guide will walk you through the steps to upgrade to Tesseract 5.3.4.
Tesseract OCR Versions
It would be helpful to know the history of the tesserOCR releases and you’ll appreciate that you could use the newest version with the LSTM (Long Short-term Memory) neural network. LSTM is a recurrent neural network (RNN) that aims to deal with the vanishing gradient problem present in traditional RNNs.
Below is a table outlining the evolution of Tesseract OCR from versions 1 to 5, highlighting the key differences and improvements introduced in each major release.
| Feature/Version | Tesseract 1 | Tesseract 2 | Tesseract 3 | Tesseract 4 | Tesseract 5 |
|---|---|---|---|---|---|
| Release Year | 1995 | 2006 | 2010 | 2018 | 2021 |
| OCR Engine | Initial release, basic OCR capabilities | Improvement in OCR algorithms | Introduction of Adaptive Recognition and improved layout analysis | Introduction of LSTM neural networks for OCR, significantly improving accuracy | Continued improvements and optimizations on LSTM, better performance and accuracy |
| Accuracy | Basic, mainly for clean printed text | Improved accuracy over version 1 | Further improvements, especially with adaptive recognition for various fonts and languages | Major leap in accuracy, capable of handling a wide range of text types, including noisy backgrounds | Slight improvements in accuracy and efficiency over version 4, with optimizations for speed and resource usage |
| Supported Languages | Limited | Expanded language support | Broad language support, introduction of training tools for additional languages | Comprehensive language support with improved LSTM models for better recognition | Further expansion and refinement of language models, ensuring better accuracy across languages |
| Performance | Basic, suitable for simple OCR tasks | Faster processing than version 1 | Improved performance and stability | Enhanced processing speed and accuracy with the LSTM model | Optimizations for even faster processing and efficiency, support for modern hardware |
| Usability | Command-line tool with limited options | Enhanced command-line options and usability | API improvements, better documentation, and usability enhancements | Significant improvements to the API for developers, introduction of a more user-friendly command-line interface | Continued enhancements to usability, with further refinements to the API and command-line tools |
| Training Tools | Not available | Not available | Improved tools for training on custom fonts and languages | Advanced training tools for LSTM models, allowing for custom model creation | Updated training tools, documentation, and support for easier custom model training |
| Application Scope | Limited to clean printed text | Expanded applicability to a wider range of printed texts | Applicable to a broader range of documents, including those with complex layouts | Suited for a wide variety of OCR tasks, including challenging conditions and text types | Ideal for almost all OCR tasks, with state-of-the-art accuracy and efficiency |
This table illustrates the continuous development and enhancement of Tesseract OCR, demonstrating its growth from a basic OCR tool to a sophisticated, neural network-based OCR engine that is one of the most powerful open-source options available today.
Removing Previous Versions
Before installing the new version, it’s crucial to remove any existing installations of Tesseract OCR to avoid conflicts. This can be achieved with the following command:
sudo apt remove --autoremove tesseract-ocr tesseract-ocr-*
This command ensures that all versions of Tesseract OCR and its associated packages are completely removed from your system.
Understanding and Adding the PPA
You may build tesseract-ocr5 from source code, and it takes time and you might run into unexpected issues. Instead, we’ll rely on the Personal Package Archive (PPA) built by other developers. PPAs allow Ubuntu users to install and upgrade software that is unavailable in the official Ubuntu repositories. For Tesseract OCR version 5, we rely on a PPA provided by Alexander Pozdnyakov:
sudo add-apt-repository ppa:alex-p/tesseract-ocr5 sudo apt update
Adding this PPA updates your system’s software sources, enabling access to newer versions of Tesseract OCR. The information about this PPA is stored in /etc/apt/sources.list.d/, which apt-get uses to fetch package updates.
If you would like to install the development branch, you can add ppa:alex-p/tesseract-ocr-devel.
Installing Tesseract OCR 5
With the PPA added, installing Tesseract OCR version 5.3.4 becomes straightforward:
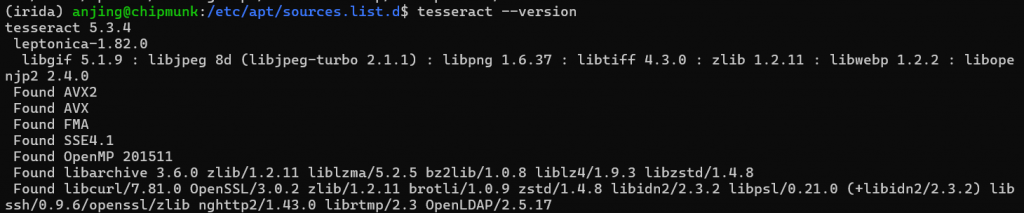
sudo apt update sudo apt install tesseract-ocr tesseract --version
These commands refresh your package list and install the latest Tesseract OCR, granting you access to all the new features and improvements of version 5.3.4.
Conclusion
Upgrading to Tesseract OCR 5 on Ubuntu requires removing any older versions, adding a specific PPA for access to the new version, and installing it using the apt package manager. This process ensures you’re equipped with the latest in OCR technology and ready to tackle text recognition tasks with improved accuracy and efficiency.
By understanding the role of PPAs and how they integrate with your system’s package management, you’re not just upgrading Tesseract OCR but also honing your skills in managing software on Ubuntu. Enjoy the enhanced capabilities of Tesseract OCR 5, and get more about our AI articles from here.
The command to display the version after installation is incorrect.
It should be as follows:
`tesseract-ocr –version` to `tesseract –version`
Thanks for pointing out that. You’re correct, and I have fixed the typo.